from typing import Literalimport numpy as npfrom numpy.typing import NDArrayfrom.frame import Frame, LspParametersfrom.lsp_constants import( LSP_MAIN_CODEBOOK, LSP_SUB_CODEBOOK, LSP_UNVOICED_HISTORY_WEIGHTS, LSP_VOICED_HISTORY_WEIGHTS, LSP_UNVOICED_BASE_WEIGHTS, LSP_VOICED_BASE_WEIGHTS, LSP_UNVOICED_PREDICTION_WEIGHTS, LSP_VOICED_PREDICTION_WEIGHTS, LSP_COSINE_LOOKUP_TABLE, LSP_SINE_LOOKUP_TABLE,)classMcelp:# LSP configuration constants ORDER =10# Number of LSP coefficients per frame# LSP stability constraint constants MIN_LSP_VALUE =0x29# Minimum value for first LSP MAX_LSP_VALUE =0x6452# Maximum value for last LSP MIN_LSP_SPACING =0x141# Minimum spacing between adjacent LSPs# LSP frequency domain transformation constants LSP_SCALING =0x517D# Initial scaling factor MAX_TABLE_INDEX =0x3F# Maximum lookup table index (63)# Default LSP values for initialization# fmt: off _DEFAULT_LSP_PARAMS = np.array([0x0924,0x1247,0x1B6B,0x248F,0x2DB2,0x36D6,0x3FF9,0x491D,0x5241,0x5B64],dtype=np.uint16).astype(np.int16) _DEFAULT_FREQUENCY_DOMAIN_LSP_PARAMS = np.array([0x7AD1,0x6BB0,0x53D4,0x352C,0x1237,0xEDC9,0xCAD4,0xAC2C,0x9450,0x852F],dtype=np.uint16).astype(np.int16)# fmt: ondef__init__(self)->None:"""Initialize MCELP with default state."""self._reset_state()def_reset_state(self)->None:"""Reset internal state to default values."""# 0x6C8Aself._lsp_history = np.stack([self._DEFAULT_LSP_PARAMS]*3)# 0x7BECself._current_lsp_params =self._DEFAULT_LSP_PARAMS.copy()# 0x6CB2self._latest_lsp_params =self._DEFAULT_LSP_PARAMS.copy()# 0x6F34self._current_frequency_domain_lsp_params =(self._DEFAULT_FREQUENCY_DOMAIN_LSP_PARAMS.copy())# 0x6CBCself._latest_frequency_domain_lsp_params =(self._DEFAULT_FREQUENCY_DOMAIN_LSP_PARAMS.copy())self._voiced_flag =Falsedef_get_weights(self,voiced_flag:bool,weight_type: Literal["generation","prediction"])-> tuple[np.ndarray, np.ndarray]:""" Get appropriate weights based on voice flag and weight type. Args: voiced_flag: True if frame is voiced, False otherwise weight_type: Type of weights to retrieve ("generation" or "prediction") Returns: Tuple of (base_weights, history_weights)"""# Select the appropriate base weights based on weight type and voiced flagif weight_type =="generation": base_weights_source =( LSP_VOICED_BASE_WEIGHTS if voiced_flag else LSP_UNVOICED_BASE_WEIGHTS)else:# prediction base_weights_source =( LSP_VOICED_PREDICTION_WEIGHTSif voiced_flagelse LSP_UNVOICED_PREDICTION_WEIGHTS)# Convert base weights to int16 base_weights = np.array(base_weights_source,dtype=np.uint16).astype(np.int16)# Get history weights (same for both generation and prediction) history_weights_source =( LSP_VOICED_HISTORY_WEIGHTS if voiced_flag else LSP_UNVOICED_HISTORY_WEIGHTS) history_weights = np.array(history_weights_source,dtype=np.uint16).astype( np.int16)return base_weights, history_weights# func_ca35def_enforce_minimum_lsp_separation(self,lsp_params: NDArray[np.int16],# ar2threshold:int,# ar0)->None:""" Enforce minimum separation between adjacent LSP parameters. Args: lsp_params: Array of LSP parameters to adjust threshold: Minimum separation threshold"""for i inrange(self.ORDER -1):# Calculate difference between current and next parameter difference = lsp_params[i]- lsp_params[i +1] adjusted_difference = difference + threshold# If parameters are too close, adjust them equally in opposite directionsif adjusted_difference >0: half_adjustment = adjusted_difference >>1 lsp_params[i]-= half_adjustment lsp_params[i +1]+= half_adjustment# func_c960def_apply_smoothing_filter(self,current_values: NDArray[np.int16],# ar2current_weights: NDArray[np.int16],# ar3history_values: NDArray[np.int16],# ar4history_weights: NDArray[np.int16],# ar5)-> NDArray[np.int16]:# ar1""" Apply smoothing filter to LSP parameters using weighted history. Args: current_values: Current LSP parameters current_weights: Weights for current parameters history_values: Historical LSP parameters history_weights: Weights for historical parameters Returns: Filtered LSP parameters"""# Convert to int64 to prevent overflow during calculations current_values = current_values.astype(np.int64) current_weights = current_weights.astype(np.int64) history_values = history_values.astype(np.int64) history_weights = history_weights.astype(np.int64) filtered_values = np.zeros(self.ORDER,dtype=np.uint16)for i inrange(self.ORDER): accumulator = current_values[i]* current_weights[i]for j inrange(3):# Process 3 frames of history accumulator += history_values[j][i]* history_weights[j][i]# Scale down by 2^15 filtered_values[i]= accumulator >>15return filtered_values.astype(np.int16)# func_c941def_predict_lsp_with_feedback(self,current_values: NDArray[np.int16],# ar1current_weights: NDArray[np.int16],# ar4history_values: NDArray[np.int16],# ar2history_weights: NDArray[np.int16],# ar3)-> NDArray[np.int16]:# ar5""" Predict LSP parameters with feedback mechanism. Args: current_values: Current LSP parameters current_weights: Weights for current parameters history_values: Historical LSP parameters history_weights: Weights for historical parameters Returns: Predicted LSP parameters"""# Convert to int64 to prevent overflow during calculations current_values = current_values.astype(np.int64) current_weights = current_weights.astype(np.int64) history_values = history_values.astype(np.int64) history_weights = history_weights.astype(np.int64) predicted_values = np.zeros(self.ORDER,dtype=np.uint16) feedback =0for i inrange(self.ORDER): base = current_values[i]<<16for j inrange(3):# Process 3 frames of history base -=(history_values[j][i]* history_weights[j][i])<<1 intermediate = base &0xFFFF base -= feedback feedback +=(current_weights[i]* intermediate)<<1 feedback >>=16 feedback +=(current_weights[i]*(base >>16))<<1 predicted_values[i]= feedback >>13return predicted_values.astype(np.int16)# func_c9cedef_enforce_lsp_stability_constraints(self,lsp_params: NDArray[np.int16],# ar2)->None:""" Enforce stability constraints on LSP parameters: 1. Ensure monotonic increase 2. Apply minimum/maximum value constraints 3. Ensure minimum spacing Args: lsp_params: LSP parameters to stabilize"""# Step 1: Single pass to ensure monotonic increasefor i inrange(len(lsp_params)-1):if lsp_params[i]> lsp_params[i +1]:# Swap adjacent LSPs if out of order lsp_params[i], lsp_params[i +1]= lsp_params[i +1], lsp_params[i]# Step 2: Apply minimum value constraint to first LSP lsp_params[0]=max(lsp_params[0],self.MIN_LSP_VALUE)# Step 3: Ensure minimum spacing between adjacent LSPs# Uses original values as reference to prevent cascading shiftsfor i inrange(len(lsp_params)-1): min_next_value = lsp_params[i]+self.MIN_LSP_SPACINGif lsp_params[i +1]< min_next_value: lsp_params[i +1]= min_next_value# Step 4: Apply maximum value constraint to last LSP lsp_params[-1]=min(lsp_params[-1],self.MAX_LSP_VALUE)# func_c7eedef_transform_lsp_to_frequency_domain(self,lsp_params: NDArray[np.int16]# ar2)-> NDArray[np.int16]:# ar3""" Transform LSP parameters from line-pair domain to frequency domain. Args: lsp_params: LSP parameters to transform Returns: Transformed frequency domain parameters"""# Convert lookup tables to int64 to prevent overflow cos_table =( np.array(LSP_COSINE_LOOKUP_TABLE,dtype=np.uint16).astype(np.int16).astype(np.int64)) sin_table =( np.array(LSP_SINE_LOOKUP_TABLE,dtype=np.uint16).astype(np.int16).astype(np.int64)) scaled_values = np.zeros(self.ORDER,dtype=np.uint16) lsp_params = lsp_params.astype(np.uint64)for i inrange(self.ORDER):# Initial scaling initial_product =(lsp_params[i]*self.LSP_SCALING)<<1# Calculate lookup table index and interpolation fraction table_index = initial_product >>8 table_index =min(table_index,self.MAX_TABLE_INDEX <<16)>>16 fraction =((initial_product >>16)&0xFF)<<3# Linear interpolation between lookup table values base_value = cos_table[table_index]<<16 scale_factor = sin_table[table_index] interpolation =(scale_factor * fraction).astype(np.int64)<<1 scaled_values[i]=(base_value + interpolation).astype(np.int64)>>16return scaled_values.astype(np.int16)# func_c9c2def_update_history(self,lsp_params: NDArray[np.int16],# ar2)->None:""" Update LSP parameter history by shifting and inserting new parameters. Args: lsp_params: New LSP parameters to add to history"""# Shift history array and insert new parameters at index 0# self._lsp_history: ar3self._lsp_history = np.roll(self._lsp_history,1,axis=0)self._lsp_history[0]= lsp_params.copy()# func_ce12def_generate_lsp_from_params(self,params: LspParameters):""" Generate LSP parameters from codebook indices. Args: params: LspParameters containing codebook indices and voiced flag"""# Get appropriate weights based on voiced flag is_voiced = params.voiced_flag ==1 base_weights, history_weights =self._get_weights(is_voiced,"generation")# Initialize LSP parameters lsp_params = np.zeros(self.ORDER,dtype=np.int16)# Get values from codebooks and convert to int16 main_codebook = np.array(LSP_MAIN_CODEBOOK,dtype=np.uint16).astype(np.int16) sub_codebook = np.array(LSP_SUB_CODEBOOK,dtype=np.uint16).astype(np.int16) main_value = main_codebook[params.main_index] sub_value_1 = sub_codebook[params.sub_index_1] sub_value_2 = sub_codebook[params.sub_index_2]# Combine main and sub values lsp_params[:5]= main_value[:5]+ sub_value_1[:5] lsp_params[5:]= main_value[5:]+ sub_value_2[5:]# Apply spacing adjustments# ar0 = 10, ar2 = 0x0060self._enforce_minimum_lsp_separation(lsp_params,10)# ar0 = 5, ar2 = 0x0060self._enforce_minimum_lsp_separation(lsp_params,5)# Apply smoothing filter# ar1 = 0x7BEC, ar2 = 0x0060, ar3 = 0xF205, ar4 = 0x6C8A, ar5 = 0xF1C9self._current_lsp_params =self._apply_smoothing_filter( lsp_params, base_weights,self._lsp_history, history_weights)# Update history with new parameters# ar2 = 0x0060, ar3 = 0x6C8Aself._update_history(lsp_params)# Stabilize and store results# ar2 = 0x7BECself._enforce_lsp_stability_constraints(self._current_lsp_params)# func_d071 Part 1def_generate_lsp_from_codebook(self,params: LspParameters)->None:""" Generate new LSP parameters from codebook indices. Args: params: LspParameters containing codebook indices and voiced flag"""# ar1 = 0x7BEC, ar7 = 0x6C8Aself._generate_lsp_from_params(params)# ar3(0x7BEC) -> ar2(0x6CB2)self._latest_lsp_params =self._current_lsp_params.copy()self._voiced_flag = params.voiced_flag ==1# func_d071 Part 2def_predict_lsp_parameters(self)->None:""" Predict LSP parameters based on history and current state."""# Get appropriate weights based on voiced flag base_weights, history_weights =self._get_weights(self._voiced_flag,"prediction")# Copy latest parameters to current# ar2(0x6CB2) -> ar3(0x7BEC)self._current_lsp_params =self._latest_lsp_params.copy()# Calculate predicted parameters# ar1 = 0x6CB2, ar2 = 0x6C8A, ar3 = 0xF1E7, ar4 = 0xF223, ar5 = 0x7BE2 predicted_lsp_params =self._predict_lsp_with_feedback(self._latest_lsp_params, base_weights,self._lsp_history, history_weights,)# Update history with predicted parameters# ar2 = 0x7BE2, ar3 = 0x6C8Aself._update_history(predicted_lsp_params)# func_d071defprocess_frame(self,frame: Frame)-> np.ndarray:""" Process a frame of speech data to generate or predict LSP parameters. Args: frame: Frame containing control bit and LSP parameters Returns: Frequency domain LSP parameters"""if frame.control_bit ==0:# Generate new LSP from codebookself._generate_lsp_from_codebook(frame.lsp_params)else:# Predict LSP based on historyself._predict_lsp_parameters()# Transform to frequency domain# ar2 = 0x7BEC, ar3 = 0x6F34self._current_frequency_domain_lsp_params =(self._transform_lsp_to_frequency_domain(self._latest_lsp_params))returnself._current_frequency_domain_lsp_params
と推測します。CRI とは、株式会社CRI・ミドルウェアのことで、LIVE DAM Ai (型番: DAM-XG8000; 以下、XG8) から採点ゲームなど機器の一部のソフトウェアを開発しています。一方、YAMAHA は遅くとも BB Cyber DAM (型番: DAM-G100; 以下、G100)の頃から DAM シリーズの開発に関わっています。
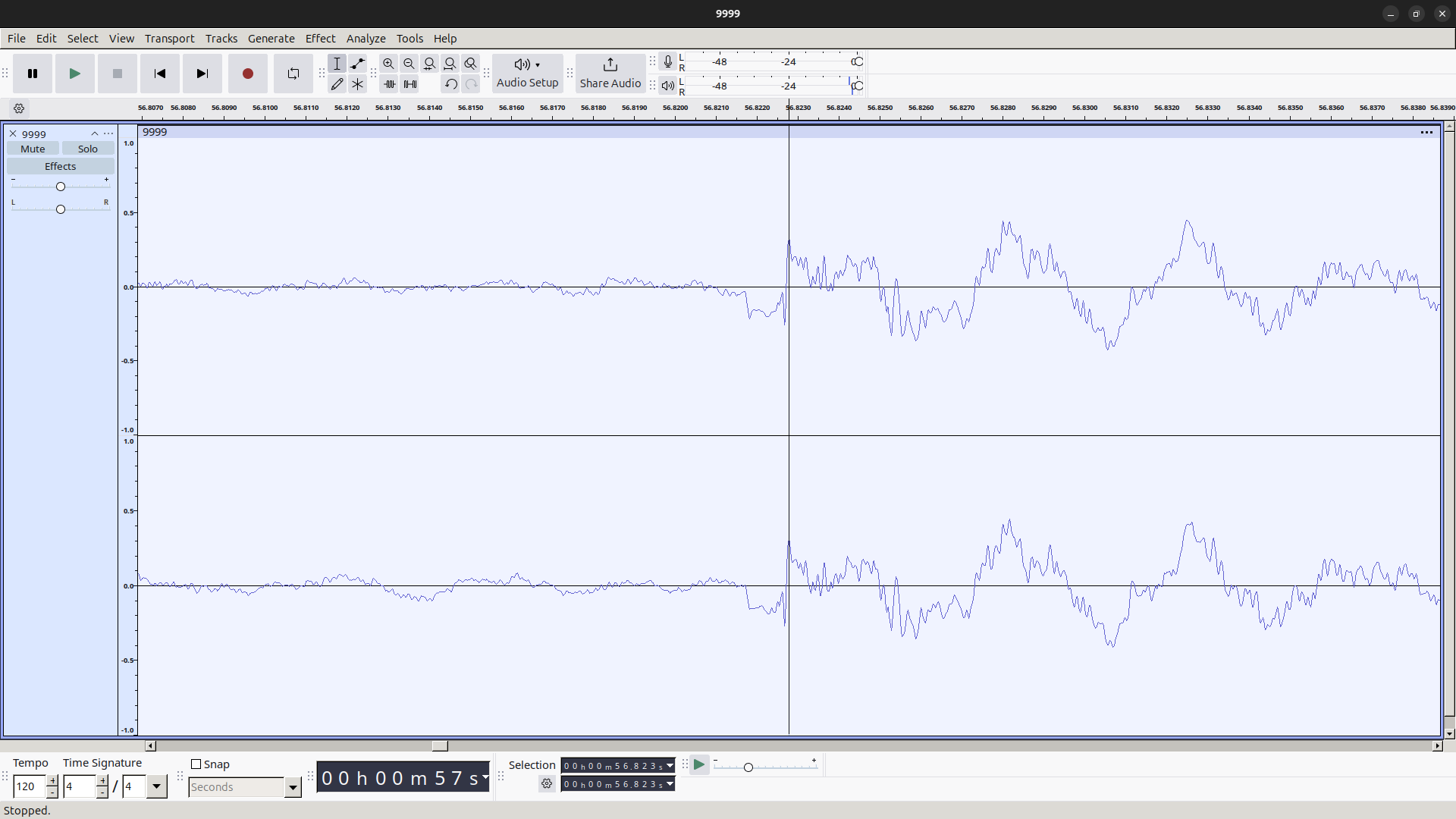
音声 A の録音時の音量、発声タイミングやフィルタ処理の微妙な違い等を考慮すると、音声 A と音声 B はほぼ同一のものであると言えます。言い換えれば、MDS の音声には従来のハードウェア MIDI 音源による出力を録音した音声も含まれているということであり、少なくとも今回検証した楽曲においては、従来の演奏方式よりも優れた音質の音声が出力されるということはないようです。